第二章 AI复兴:深度学习+大数据=人工智能(第12/14页)
深度学习大致就是这么一个用人类的数学知识与计算机算法构建起整体架构,再结合尽可能多的训练数据以及计算机的大规模运算能力去调节内部参数,尽可能逼近问题目标的半理论、半经验的建模方式。
指导深度学习的基本是一种实用主义的思想。
不是要理解更复杂的世界规律吗?那我们就不断增加整个水管网络里可调节的阀门的个数(增加层数或增加每层的调节阀数量)。不是有大量训练数据和大规模计算能力吗?那我们就让许多CPU和许多GPU(图形处理器,俗称显卡芯片,原本是专用于作图和玩游戏的,碰巧也特别适合深度学习计算)组成庞大计算阵列,让计算机在拼命调节无数个阀门的过程中,学到训练数据中的隐藏规律。也许正是因为这种实用主义的思想,深度学习的感知能力(建模能力)远强于传统的机器学习方法。
实用主义意味着不求甚解。即便一个深度学习模型已经被训练得非常“聪明”,可以非常好地解决问题,但很多情况下,连设计整个水管网络的人也未必能说清楚,为什么管道中每一个阀门要调节成这个样子。也就是说,人们通常只知道深度学习模型是否工作,却很难说出模型中某个参数的取值与最终模型的感知能力之间,到底有怎样的因果关系。
这真是一件特别有意思的事。有史以来最有效的机器学习方法,在许多人看来,竟然是一个只可意会、不可言传的“黑盒子”。
由此引发的一个哲学思辨是,如果人们只知道计算机学会了做什么,却说不清计算机在学习过程中掌握的是一种什么样的规律,那这种学习本身会不会失控?
比如,很多人由此担心,按照这样的路子发展下去,计算机会不会悄悄学到什么我们不希望它学会的知识?另外,从原理上说,如果无限增加深度学习模型的层数,那计算机的建模能力是不是就可以与真实世界的终极复杂度有一比呢?如果这个答案是肯定的,那只要有足够的数据,计算机就能学会宇宙中所有可能的知识——接下来会发生什么?大家是不是对计算机的智慧超越人类有了些许的忧虑?还好,关于深度学习到底是否有能力表达宇宙级别的复杂知识,专家们尚未有一致看法。人类至少在可见的未来还是相对安全的。
补充一点:目前,已经出现了一些可视化的工具,能够帮助我们“看见”深度学习在进行大规模运算时的“样子”。比如说,谷歌著名的深度学习框架Tensor Flow就提供了一个网页版的小工具,用人们易于理解的图示,画出了正在进行深度学习运算的整个网络的实时特征。
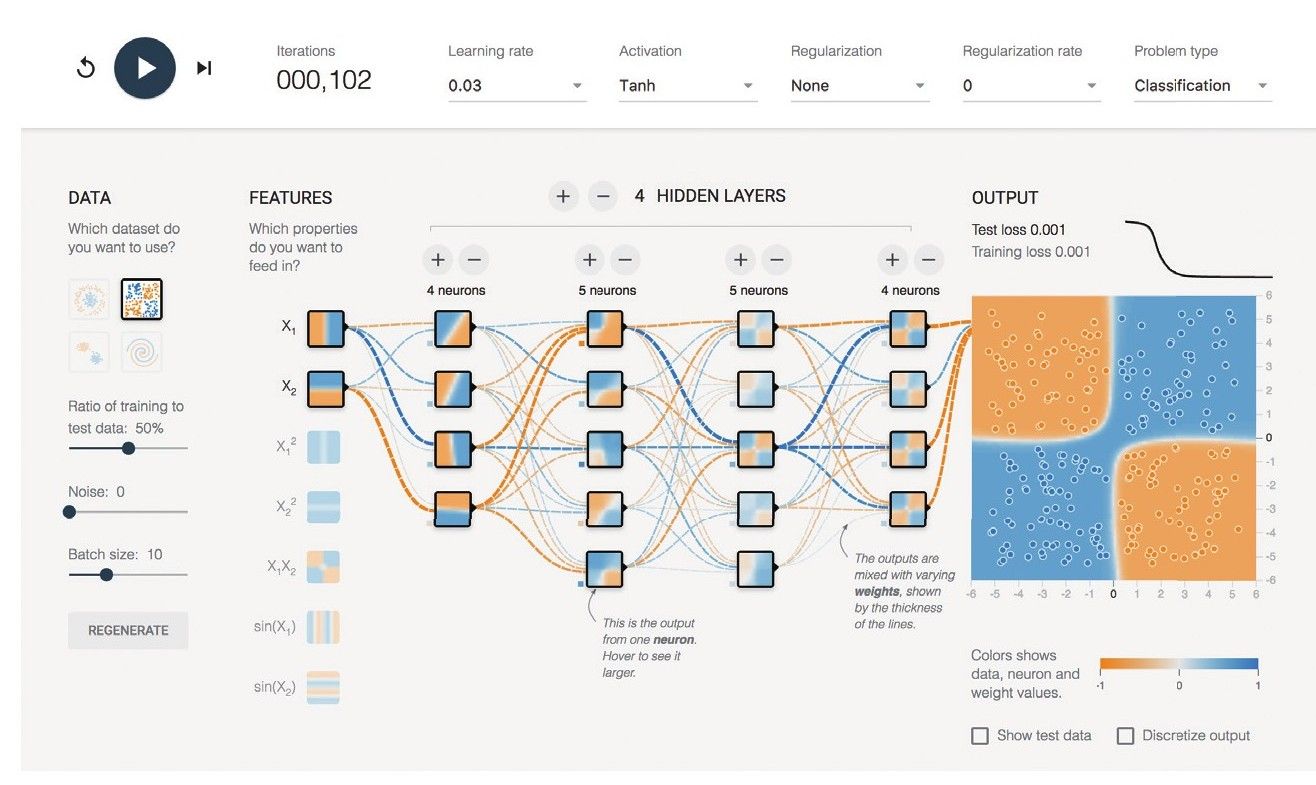
图28 训练深度学习模型时,整个深度神经网络的可视化状态48
图28显示了一个包含4层中间层级(隐含层)的深度神经网络针对某训练数据集进行学习时的“样子”。图中,我们可以直观地看到,网络的每个层级与下一个层级之间,数据“水流”的方向与大小。我们还可以随时在这个网页上改变深度学习框架的基本设定,从不同角度观察深度学习算法。这对我们学习和理解深度学习大有帮助。
最后,需要特别说明的是,以上对深度学习的概念阐述刻意避免了数学公式和数学论证,这种用水管网络来普及深度学习的方法只适合一般公众。对于懂数学、懂计算机科学的专业人士来说,这样的描述相当不完备也不精确。流量调节阀的比喻与深度神经网络中每个神经元相关的权重调整,在数学上并非完全等价。对水管网络的整体描述也有意忽略了深度学习算法中的代价函数、梯度下降、反向传播等重要概念。专业人士要学习深度学习,还是要从专业教程看起。
大数据:人工智能的基石
目前的深度学习主要是建立在大数据的基础上,即对大数据进行训练,并从中归纳出可以被计算机运用在类似数据上的知识或规律。那么,到底什么是大数据呢?
人们经常笼统地说,大数据就是大规模的数据。
这个说法并不准确。“大规模”只是指数据的量而言。数据量大,并不代表着数据一定有可以被深度学习算法利用的价值。例如,地球绕太阳运转的过程中,每一秒钟记录一次地球相对太阳的运动速度、位置,这样积累多年,得到的数据量不可谓不大,但是,如果只有这样的数据,其实并没有太多可以挖掘的价值,因为地球围绕太阳运转的物理规律,人们已经研究得比较清楚了,不需要由计算机再次总结出万有引力定律或广义相对论来。
那么,大数据到底是什么?大数据是如何产生的?什么样的数据才最有价值,最适合作为计算机的学习对象呢?
根据马丁·希尔伯特(Martin Hilbert)的总结49,今天我们常说的大数据其实是在2000年后,因为信息交换、信息存储、信息处理三个方面能力的大幅增长而产生的数据:
·信息交换:据估算,从1986年到2007年这20年间,地球上每天可以通过既有信息通道交换的信息数量增长了约217倍,这些信息的数字化程度,则从1986年的约20%增长到2007年的约99.9%50。在数字化信息爆炸式增长的过程里,每个参与信息交换的节点都可以在短时间内接收并存储大量数据。这是大数据得以收集和积累的重要前提条件。例如,根据对社交网站Twitter的统计,全球范围内每秒钟新增的推文条数约6000条,每分钟约350000条,每天约5亿条,每年约2000亿条。在网络带宽大幅提高之前,这个规模的信息交换是不可想象的。
·信息存储:全球信息存储能力大约每3年翻一番。从1986年到2007年这20年间,全球信息存储能力增加了约120倍,所存储信息的数字化程度也从1986年的约1%增长到2007年的约94%。1986年时,即便用上我们所有的信息载体、存储手段,我们也不过能存储全世界所交换信息的大约1%,而2007年这个数字已经增长到大约16%。信息存储能力的增加为我们利用大数据提供了近乎无限的想象空间。例如,谷歌这样的搜索引擎,几乎就是一个全球互联网的“备份中心”,谷歌的大规模文件存储系统完整保留了全球大部分公开网页的数据内容,相当于每天都在为全球互联网做“热备份”。
·信息处理:有了海量的信息获取能力和信息存储能力,我们也必须有对这些信息进行整理、加工和分析的能力。谷歌、Facebook、亚马逊、百度、阿里等公司在数据量逐渐增大的同时,也相应建立了灵活、强大的分布式数据处理集群。数万台乃至数十万台计算机构成的并行计算集群每时每刻都在对累积的数据进行进一步加工和分析。谷歌的分布式处理三大利器——GFS、Map Reduce和Bigtable就是在大数据的时代背景下诞生并成为绝大多数大数据处理平台的标准配置。利用这些数据处理平台,谷歌每天都会将多达数百亿的搜索记录清理、转换成便于数据分析的格式,并提供强有力的数据分析工具,可以非常快地对数据进行聚合、维度转换、分类、汇总等操作。