第五章 机遇来临:AI先行的创新与创业(第7/10页)
根据汪华的判断,我们目前正在进入AI商业化的第一个阶段,也许只需要3年左右的时间,AI就可以在各种在线业务中得到普及。AI商业化的第二个阶段,要花五六年、六七年的时间才能充分发展起来。而标志着全面自动化的第三阶段,也许需要十几年或更长的时间。
就像过去20年互联网和移动互联网的商业化所走过的历程一样,人工智能的商业化会以自己的节奏,分阶段、分步骤地渗透到人类生产、生活的方方面面。而且,AI对整个社会的改变,可能比过去20年互联网革命所带来的改变要大得多。能否准确把握AI商业化的脉络,是AI时代的创业能否站在“风口”上的关键。
AI创业的五大基石
每个时代的创业有每个时代的特点。人工智能创业就与此前的互联网时代创业、移动互联网时代创业很不相同。
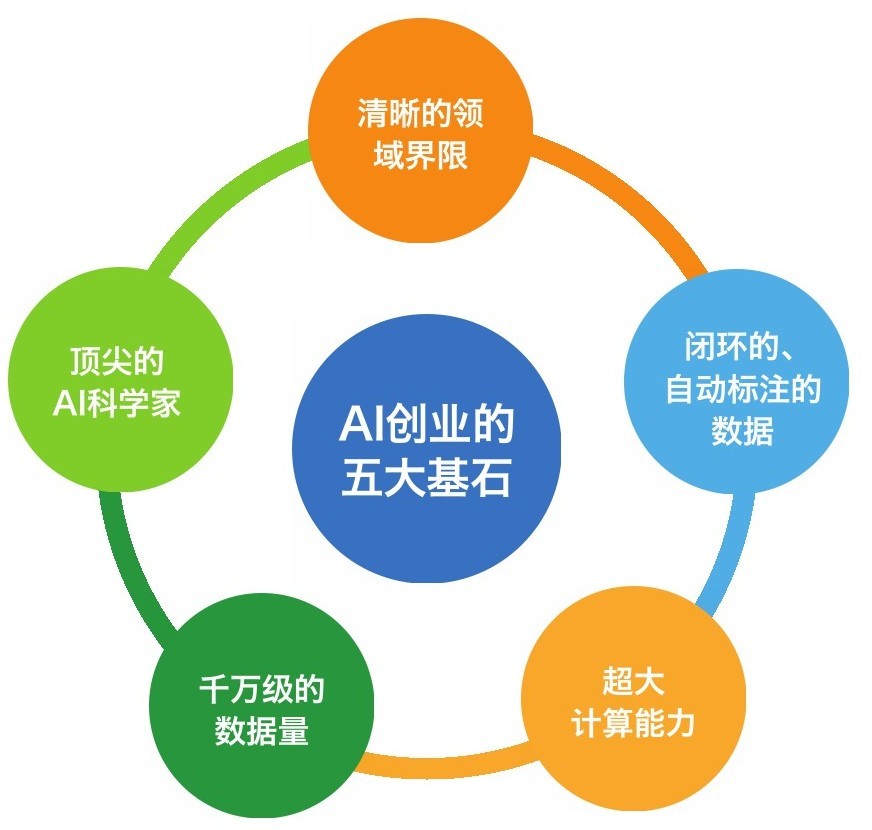
图58 人工智能创业的五大基石
按照我的归纳和总结,人工智能时代的创业有五个前提条件:
·清晰的领域界限:人工智能创业,要解决的领域问题一定要非常清晰,有明确的领域边界,因为这一类问题是今天以深度学习为代表的人工智能算法最善于解决的。例如,同样是做机器人,如果做一个借助视觉传感器更好地规划扫地线路、提高清洁效率的扫地机器人,将机器人的需求限定在一个有限的问题边界内,这样的解决方案就相对靠谱;如果上来就要做一个长得像人一样、可以与人交流的人形机器人,那以今天的技术,做出来的多半不是人工智能,而是“人工智障”。
·闭环的、自动标注的数据:针对要用AI解决的领域问题,最好要在这个领域内,有闭环的、自动标注的数据。例如,基于互联网平台的广告系统可以自动根据用户点击以及后续操作,收集到第一手转化率数据,而这个转化率数据反过来又可以作为关键特征,帮助AI系统进一步学习。这种从应用本身收集数据,再用数据训练模型,用模型提高应用性能的闭环模式更加高效。谷歌、百度等搜索引擎之所以拥有强大的人工智能潜力,就是因为它们的业务,比如搜索和广告本身就是一个闭环的系统,系统内部就可以自动完成数据收集、标注、训练、反馈的全过 程。
·千万级的数据量:今天人工智能的代表算法是深度学习。而深度学习通常要求足够数量的训练数据。一般而言,拥有千万级的数据量是保证深度学习质量的前提。当然,这个“千万级”的定义过于宽泛。事实上,在不同的应用领域,深度学习对数据量的要求也不尽相同。而且,也不能仅看数据记录的个数,还要看每个数据记录的特征维数,特征在相应空间中的分布情况,等等。
·超大规模的计算能力:深度学习在进行模型训练时,对电脑的计算能力有着近乎“痴狂”的渴求。创新工场曾经给一个专注于研发深度学习技术的团队投资了1000万元人民币。结果,团队建设初期才两三个月时间,仅购买深度学习使用的计算服务器就花掉了700多万元。今天,一个典型的深度学习任务,通常都要求在一台或多台安装有4块甚至8块高性能GPU芯片的计算机上运行。涉及图像、视频的深度学习任务,则更是需要数百块、数千块GPU芯片组成的大型计算集群。在安装了大型计算集群的机房内,大量GPU在模型训练期间发出远比普通服务器多数十倍的热量。许多机房的空调系统都不得不重新设计、安装。在一些空调马力不足的机房里,创业团队甚至购买了巨大的冰块来协助降温。
·顶尖的AI科学家:今天的人工智能研发还相当依赖于算法工程师甚至是AI科学家的个人经验积累。水平最高的科学家与普通水平的算法工程师之间,生产力的差异不啻千百倍。人工智能创业公司对顶尖AI科学家的渴求直接造成了这个领域科学家、研究员的身价与日俱增。谷歌雇用杰弗里·辛顿、李飞飞,Facebook雇用扬·勒丘恩,据说都开出了数百万美元的年薪。国内AI创业公司如旷视科技,也用令人瞠目的高薪,将机器视觉领域的顶尖科学家孙剑“挖”了过来,担任公司的首席科学家。
AI创业的泡沫现象及六大挑战
当然,看到人工智能创业机遇的同时,我们也必须保持足够清醒的头脑。2016年到2017年,人工智能的创业和投资明显存在无序、失衡、过热的情况。人们常常担忧的泡沫现象的确存在。
看一看如星火燎原一般在美国、中国、以色列等地建立的自动驾驶创业团队吧,自动驾驶这个行业确实巨大,但真的需要那么多早期创业团队吗?要做一个第4级或第5级的自动驾驶,技术难度异常大,非要投入巨资和最顶尖的研发人才不可。那么,这么多初创的自动驾驶团队里,究竟有几个是可以在自动驾驶普及的那一天幸存下来并成长为行业巨人的呢?
家用机器人的概念就更别提了。那么多号称开始研发家用机器人的公司,如果是做亚马逊Echo那样限定使用场景的智能家电还好说,如果上来就要做语言交流、人形外观的机器人,那几乎一定会因为技术水平无法达到人类用户的预期而走向失败。这道理很好理解,越是长得像人的机器人,用户就越是会用人的标准去衡量、评价它,希望越大,失望也就越大。
语音和自然语言处理方面的创业也有类似问题。今天的语音识别虽然做得相当不错,但机器的能力仅限于感知领域,只能完成听写这种以转录为主的任务。也就是说,机器目前只能很有效地将语音转换为文字,但根本无法直接理解文字的含义。只有限定一个非常特定的领域,技术才能解决问题,如果要求自然语言处理算法支持通用的人机对话,那就不切实际了。目前有许多从事智能客服、智能聊天机器人创业的团队,这些团队如果不善于界定问题领域,就很容易将需求问题变复杂,以至于人工智能技术也爱莫能助。
基于人脸识别技术的身份认证、安防类应用是中国人工智能创业的特色领域,并已经产生了至少四家独角兽或接近独角兽规模的创业公司。但这个领域的市场空间绝对不会像自动驾驶那么宽广,目前二三十家公司都要削尖脑袋挤进人脸识别市场的情况显然是过热了。
基于人工智能的辅助医疗诊断刚刚起步,就出现了一大批瞄准这一方向的创业公司。但只要是熟悉医疗行业的人都很清楚,在这个行业里,要得到闭环的、有标注的、数据量足以发挥深度学习效能的医疗大数据,其难度远超普通人的想象。没有符合要求的医疗数据,人工智能又该从何谈起?所以,在智能医疗领域,今后可以成功的初创公司,一定是那些既懂人工智能算法,又特别了解医疗行业,可以收集到高质量医疗数据的公司。